When to use it
A product team has a weekly or launch readout and needs to explain movement in activation, engagement, retention, conversion, or revenue metrics without overstating the signal.
Diagnostic Workflow
Decide whether product metric movement is meaningful enough to brief the team, adjust the roadmap, or keep the metric in monitoring.
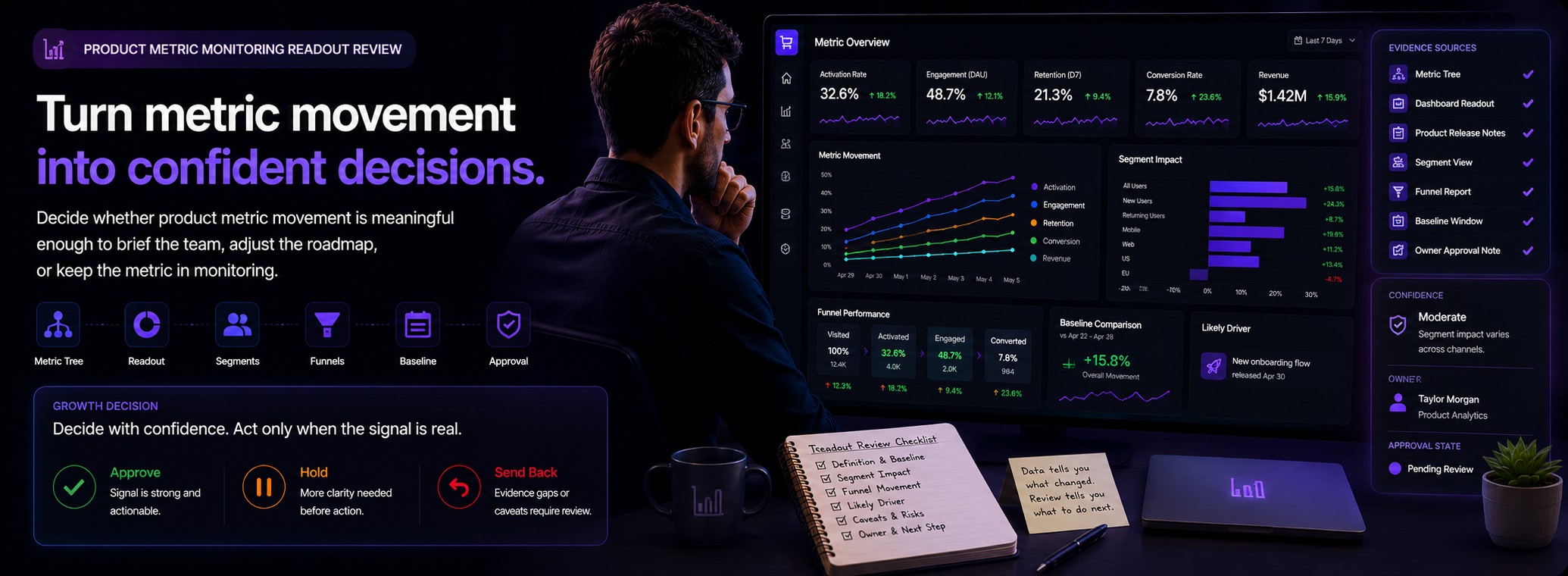
Decision frame
Decide whether product metric movement is meaningful enough to brief the team, adjust the roadmap, or keep the metric in monitoring. The proof gate for this route is: Metric readout memo with definition, baseline, movement, segment caveat, likely driver, owner, and approval state.. The page is not asking the analyst to produce a generic audit. It is asking for a decision-ready product analytics memo that can be reviewed by a product, analytics, or growth owner.
A product team has a weekly or launch readout and needs to explain movement in activation, engagement, retention, conversion, or revenue metrics without overstating the signal.
OpenAnalyst should review Product Metric Monitoring Readout Review, compare the decision evidence with the caveats, and keep the next recommendation approval-gated until the reviewer accepts it.
A product metric monitoring readout review evaluates whether metric movement is meaningful enough to brief the team, adjust the roadmap, or keep the signal in monitoring. The review separates observed movement from interpretation so the team does not escalate a dashboard fluctuation into a roadmap change before validating the evidence.
Many teams react too quickly to temporary movement without confirming metric definition stability, baseline quality, segment behavior, likely drivers, or confidence state. The readout exists to slow that reaction down and produce a decision-ready memo that can be reviewed by a product, analytics, or growth owner.
A decision to brief the team or adjust the roadmap should not be triggered by every metric movement. It should be triggered by evidence that the definition, baseline, segment scope, driver, and confidence state support a meaningful readout.
Many monitoring failures occur because teams compare metrics whose definition, tracking logic, attribution behavior, or calculation structure changed during the comparison period. A metric that appears to move may actually reflect a definition change rather than a behavioral shift.
The review confirms the metric definition, calculation methodology, tracking consistency, reporting source alignment, and time-window stability. If the definition changed recently, the movement should remain caveated until the comparison becomes reliable.
Metric definition should be confirmed before movement is interpreted. An unstable definition makes every downstream comparison unreliable regardless of how large the movement appears.
Movement becomes meaningful only when compared against a stable baseline. Comparison periods should be aligned for seasonality, campaign overlap, launch timing, and historical variance. If the baseline is missing or unstable, the metric belongs in monitoring rather than action.
The review confirms whether the comparison window is clean and comparable. A sudden increase in engagement during a launch week may look significant, but without a matched comparison period, the signal may be temporary or misleading.
A stable baseline ensures the movement signal is real rather than an artifact of poor comparison. Movement without a baseline can be watched but should not trigger roadmap or growth action.
Not all movement deserves escalation. Expected variance, temporary volatility, tracking instability, and operational anomalies can produce dashboard movement that looks significant but remains inside normal ranges. The review distinguishes between noise and a meaningful behavioral change.
The workflow should avoid turning every dashboard fluctuation into a roadmap discussion. If the movement remains inside normal variance ranges, the recommendation may stay in monitoring rather than triggering a team briefing.
Signal should be confirmed before action. Reacting to normal variance as if it were meaningful change creates false narratives and wastes team attention on movement that reverts without intervention.
Movement should connect to a likely operational or product driver whenever possible. The review compares the metric movement against product releases, UX updates, experiment launches, traffic changes, acquisition campaigns, technical incidents, and pricing changes.
If the reviewer cannot explain the likely driver, the recommendation should remain partially held. Unexplained movement should not automatically trigger roadmap changes or team briefings. The driver provides the causal link that transforms observation into actionable insight.
A likely driver gives the readout explanatory power. Movement without an identified cause should carry lower confidence and may belong in monitoring until the driver becomes clear.
Aggregate metrics often hide important segment differences. A product may show stable activation overall while declining sharply for mobile users, specific acquisition channels, or particular subscription tiers. The review inspects segment-level behavior before making claims about the broader population.
If one segment or driver explains most of the movement, the recommendation should stay scoped to that context. Aggregate claims should remain caveated until the broader population is checked. Generalizing a segment-specific signal produces recommendations that break when applied outside the affected group.
Segment review ensures the readout does not overstate a narrow signal. A movement driven by one segment should be reported as such, and action should be scoped accordingly rather than applied across the entire product.
The readout should communicate confidence clearly. Confidence depends on metric stability, tracking reliability, segment consistency, baseline quality, and operational alignment. The review assigns a confidence level so the reader understands whether the signal is strong enough to support the recommended action.
If confidence remains weak, the workflow should prevent the team from overreacting. A low-confidence signal may warrant continued monitoring or additional validation but should not trigger roadmap changes, team briefings, or campaign adjustments.
Confidence state should match the evidence quality. A strong signal with high confidence supports action. A weak signal with low confidence should stay in monitoring or trigger additional validation rather than immediate follow-up.
Decision-makers should see monitoring limitations alongside the movement findings. Caveats around tracking limitations, segment instability, baseline uncertainty, release overlap, sampling issues, and confidence constraints should remain attached to the recommendation throughout the review process.
If caveats disappear from the readout, the next step looks safer than the evidence allows. Each finding should carry its limitation so the reviewer can weigh confidence alongside the observed movement.
Visible caveats improve trust by helping stakeholders understand the limitations behind the metric movement. The review should not approve roadmap changes or team briefings when significant caveats remain unresolved.
Product metric movement influences roadmap priorities, team briefings, campaign launches, and growth investments simultaneously. An approval-gated review ensures the team does not confuse dashboard visibility with decision readiness when interpreting metric movement.
The reviewer should approve only the next step supported by visible metric evidence. If definition stability, baseline quality, segment review, driver identification, or confidence state evidence is not visible, the output should be a hold or monitoring note rather than a roadmap or briefing approval.
Approval gating protects product teams from acting on metric movement when the underlying definition, baseline, segment, driver, and confidence evidence remains incomplete. The review should answer a clear decision: brief the team, adjust the roadmap, or keep the metric in monitoring.
It is ready when the metric definition is stable, the comparison window is clear, movement exceeds an agreed threshold, and segment caveats are visible. Without those conditions, the signal belongs in monitoring. The practical test is whether the evidence, caveat, and owner are clear enough for a reviewer to approve the next step without guessing.
It should hold the recommendation and ask for a baseline or comparison window. Movement without a baseline can still be watched, but it should not trigger roadmap or growth action. The practical test is whether the evidence, caveat, and owner are clear enough for a reviewer to approve the next step without guessing.
If one segment or driver explains the movement, the recommendation should be scoped to that context. Aggregate claims should stay caveated until the broader population is checked. The practical test is whether the evidence, caveat, and owner are clear enough for a reviewer to approve the next step without guessing.
No. The readout needs a definition, baseline, movement read, caveat, likely driver, owner, and approval state before it supports action. The practical test is whether the evidence, caveat, and owner are clear enough for a reviewer to approve the next step without guessing.