When to use it
A growth lead or founder is reviewing LinkedIn DM outreach results before increasing volume, changing the message, handing the process to a team member, or adding automation.
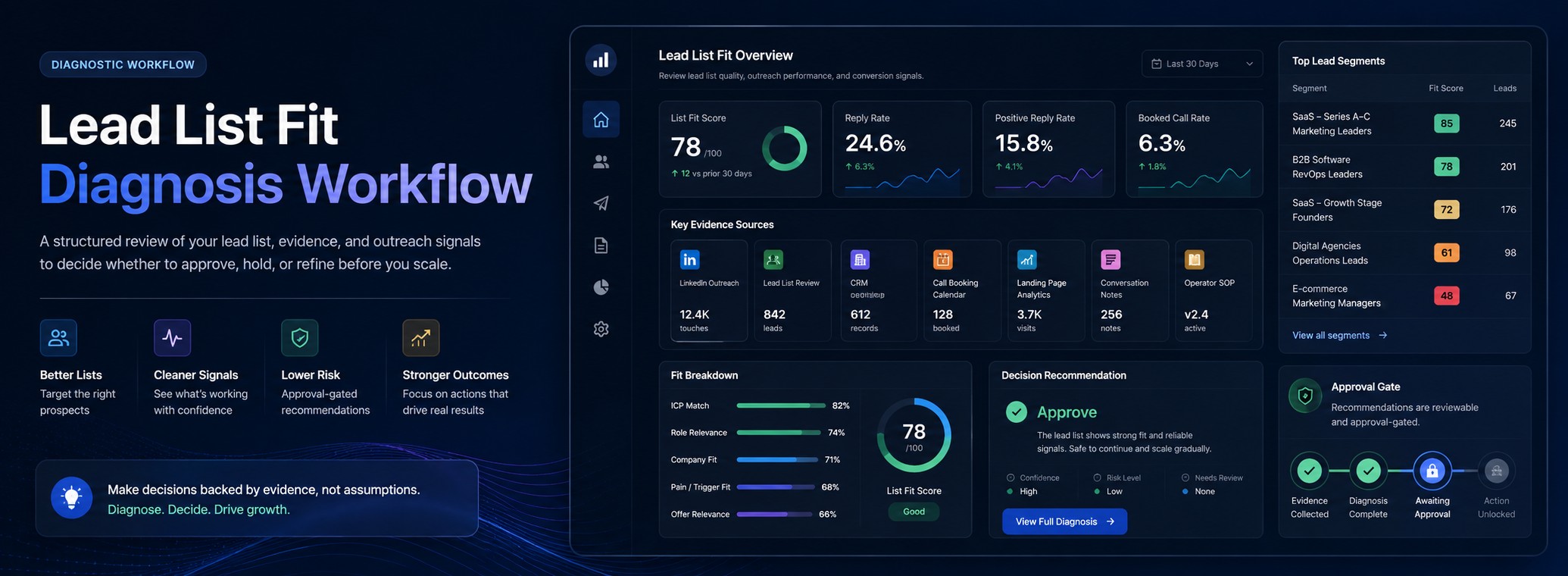
Diagnostic Workflow
Use OpenAnalyst to review lead list fit diagnosis workflow with evidence checks, caveats, anonymized operating patterns, and approval boundaries before action.
Decision frame
Decide whether the list should be refined before changing the message or offer.
A growth lead or founder is reviewing LinkedIn DM outreach results before increasing volume, changing the message, handing the process to a team member, or adding automation.
OpenAnalyst should review Lead List Fit Diagnosis Workflow, compare the decision evidence with the caveats, and keep the next recommendation approval-gated until the reviewer accepts it.
A lead list can make or break an outbound campaign before the first message is sent. If the list is weak, even strong copy, a clear offer, and consistent follow-up may produce poor results. If the list is strong, the team can interpret acceptance rates, replies, booked calls, objections, and conversion signals with more confidence.
The Lead List Fit Diagnosis Workflow helps a founder, growth lead, or sales operator decide whether the list should be refined before changing the message, offer, automation, or outreach volume. Instead of treating weak LinkedIn DM results as a copywriting problem by default, this workflow checks whether the right prospects were selected in the first place.
The core decision is simple: approve the current list, hold the campaign, or send the list back for refinement before the next marketing action.
Use this workflow when outreach performance is unclear and the team is tempted to change the message, increase volume, hand the process to another operator, or add automation. It is especially useful when LinkedIn outreach data, CRM notes, call-booking calendars, landing page analytics, conversation notes, and the operator SOP tell an incomplete story.
The workflow helps separate list-quality problems from message-quality problems, offer-positioning problems, tracking problems, and operating problems. That distinction matters because changing the wrong lever can make the campaign worse. A better message will not fix a list of prospects who do not feel the pain. More volume will not fix a broken offer handoff. Automation will not improve results if the process is unstable.
The reviewer should start with visible evidence, not opinion. Each input should answer a specific part of the fit question.
Before judging performance, the team should confirm who the campaign was meant to reach. A lead list should not only contain plausible buyers. It should contain prospects who match the specific decision profile the campaign was built for.
For example, if the offer is designed for B2B SaaS founders with active outbound sales motions, the list should not be filled with agencies, ecommerce stores, consultants, or companies without visible sales activity. Those may be real businesses, but they may not be the right audience for this campaign.
If these signals are missing, the next recommendation should be list refinement, not a message rewrite.
A poor response rate does not automatically mean the message is bad. It may mean the message was sent to the wrong people. The workflow should separate these issues before recommending a next action.
If prospects match the target segment but do not respond, the message style, offer angle, or first-message posture may need testing. If prospects do not match the target segment, the message data is less reliable. The team cannot judge message quality from an audience that was unlikely to care.
Not all replies are useful. A campaign may receive responses that do not indicate real buying interest. The reviewer should look at the quality of conversations, not only the number of replies.
Strong response quality may include relevant decision makers, clear pain recognition, requests for more information, booked calls, or objections that can be handled. Weak response quality may include confusion, irrelevant replies, vendor pitches, unqualified contacts, or prospects who clearly do not match the offer.
If the wrong people are responding, refine the list. If the right people are responding but not moving forward, the issue may be proof, CTA clarity, follow-up, or the offer handoff.
A lead list diagnosis should not stop at the first message. The team should also check whether interested prospects have a clear path from conversation to next step. Sometimes the list is strong and the message creates interest, but the campaign fails because the handoff is unclear.
If the offer handoff is unclear, the team should fix the handoff before changing prospecting volume.
The team should only make confident decisions when tracking is clean enough to isolate the constraint. If outreach volume, acceptance rates, replies, booked calls, landing page visits, and CRM updates are disconnected, the recommendation should stay caveated.
Poor tracking can make the wrong lever look broken. A team may think the list is weak when the real issue is no follow-up. Or they may think the offer is weak when booked-call data was not updated correctly. The workflow should also separate a funnel leak from an operating leak, such as no owner, weak delivery, missing promotion, or unstable execution.
After reviewing the evidence, the workflow should produce a clear decision.
The recommendation should always include the caveat. If an important input is missing or contradicted, the output should be a review note, not an execution instruction. OpenAnalyst can summarize evidence and suggest the next action, but the recommendation should remain approval-gated until a reviewer accepts it.
The best use of this workflow is to prevent the team from changing the wrong lever. If the list is the constraint, refine the list. If the message is the constraint, test the message. If the offer handoff is unclear, clarify the next step. If tracking is weak, improve measurement before making a scale decision.
A strong Lead List Fit Diagnosis Workflow keeps outbound decisions tied to evidence. It protects the campaign from premature scaling, weak assumptions, and generic recommendations while helping the reviewer decide whether the next growth action is ready, caveated, or still on hold.
No. The public recommendation should stay reviewable and approval-gated until a reviewer accepts the action. For Lead List Fit Diagnosis Workflow, the practical answer is to keep the recommendation tied to visible evidence and a named approval boundary. If the input is missing or contradicted, the page should produce a caveated review note, not an execution instruction.
The page should keep the recommendation caveated and name the missing context before proposing follow-up. For Lead List Fit Diagnosis Workflow, the practical answer is to keep the recommendation tied to visible evidence and a named approval boundary. If the input is missing or contradicted, the page should produce a caveated review note, not an execution instruction.
If the segment is not stable, refine the list before rewriting the offer or increasing volume. For Lead List Fit Diagnosis Workflow, the practical answer is to keep the recommendation tied to visible evidence and a named approval boundary. If the input is missing or contradicted, the page should produce a caveated review note, not an execution instruction.
If response quality is below threshold, run a message variant test before handing the sequence to automation. For Lead List Fit Diagnosis Workflow, the practical answer is to keep the recommendation tied to visible evidence and a named approval boundary. If the input is missing or contradicted, the page should produce a caveated review note, not an execution instruction.
If the offer handoff is unclear, draft a handoff fix before changing prospecting volume. For Lead List Fit Diagnosis Workflow, the practical answer is to keep the recommendation tied to visible evidence and a named approval boundary. If the input is missing or contradicted, the page should produce a caveated review note, not an execution instruction.
If the data cannot isolate the constraint, keep the recommendation as a test plan rather than a scale decision. For Lead List Fit Diagnosis Workflow, the practical answer is to keep the recommendation tied to visible evidence and a named approval boundary. If the input is missing or contradicted, the page should produce a caveated review note, not an execution instruction.